この jupyter notebook ファイルは ISSP Data Repository (master branch) から入手できます。
ガウス過程
PHYSBOではガウス過程回帰を実行しながらベイズ最適化を行なっています。
そのため、学習データが与えられた際にガウス過程回帰を実行することもでき、学習済みモデルを利用したテストデータの予測も行うことができます。
ここでは、その手順について紹介します。
[1]:
import numpy as np
import matplotlib.pyplot as plt
import physbo
探索候補データの準備
本チュートリアルでは例として、Cuの安定した界面構造の探索問題を扱います。 目的関数の評価にあたる構造緩和計算には、実際には1回あたり数時間といったオーダーの時間を要しますが、本チュートリアルでは既に評価済みの値を使用します。問題設定については、以下の文献を参照してください。 S. Kiyohara, H. Oda, K. Tsuda and T. Mizoguchi, “Acceleration of stable interface structure searching using a kriging approach”, Jpn. J. Appl. Phys. 55, 045502 (2016).
データセットファイル s5-210.csv を保存し、次のように読み出します。
[2]:
def load_data():
A = np.asarray(np.loadtxt('s5-210.csv',skiprows=1, delimiter=',') )
X = A[:,0:3]
t = -A[:,3]
return X, t
X, t = load_data()
X = physbo.misc.centering( X )
X.shape
[2]:
(17982, 3)
学習データの定義
対象データのうち、ランダムに選んだ1割をトレーニングデータとして利用し、別のランダムに選んだ1割をテストデータとして利用します。
[3]:
np.random.seed(12345)
N = len(t)
Ntrain = int(N*0.1)
Ntest = min(int(N*0.1), N-Ntrain)
id_all = np.random.choice(N, N, replace=False)
id_train = id_all[0:Ntrain]
id_test = id_all[Ntrain:Ntrain+Ntest]
X_train = X[id_train]
X_test = X[id_test]
t_train = t[id_train]
t_test = t[id_test]
print("Ntrain =", Ntrain)
print("Ntest =", Ntest)
Ntrain = 1798
Ntest = 1798
ガウス過程の学習と予測
以下のプロセスでガウス過程を学習し、テストデータの予測を行います。
ガウス過程のモデルを生成します。
X_train(学習データのパラメータ), t_train(学習データの目的関数値)を用いてモデルを学習します。
学習されたモデルを用いてテストデータ(X_test)に対する予測を実行します。
共分散の定義(ガウシアン)
[4]:
cov = physbo.gp.cov.Gauss( X_train.shape[1],ard = False )
平均の定義
[5]:
mean = physbo.gp.mean.Const()
尤度関数の定義(ガウシアン)
[6]:
lik = physbo.gp.lik.Gauss()
ガウス過程モデルの生成
[7]:
gp = physbo.gp.Model(lik=lik,mean=mean,cov=cov)
config = physbo.misc.SetConfig()
ガウス過程モデルを学習
[8]:
gp.fit(X_train, t_train, config)
Start the initial hyper parameter searching ...
Done
Start the hyper parameter learning ...
0 -th epoch marginal likelihood 16183.326658360042
50 -th epoch marginal likelihood 3766.734249925179
100 -th epoch marginal likelihood 1450.3500890285495
150 -th epoch marginal likelihood 127.98987541463339
200 -th epoch marginal likelihood -665.714179830029
250 -th epoch marginal likelihood -1132.4472253356018
300 -th epoch marginal likelihood -1340.5546244777697
350 -th epoch marginal likelihood -1438.398304111003
400 -th epoch marginal likelihood -1464.575163347392
450 -th epoch marginal likelihood -1478.4817552781674
500 -th epoch marginal likelihood -1485.7013807794137
Done
学習されたガウス過程におけるパラメタを出力
[9]:
gp.print_params()
likelihood parameter = [-2.44630277]
mean parameter in GP prior: [-1.06536273]
covariance parameter in GP prior: [-0.64183368 -2.49190006]
テストデータの平均値(予測値)および分散を計算
[10]:
gp.prepare(X_train, t_train)
fmean = gp.get_post_fmean(X_train, X_test)
fcov = gp.get_post_fcov(X_train, X_test)
予測の結果
[11]:
fmean
[11]:
array([-1.04749842, -0.99756623, -1.09935748, ..., -1.07561436,
-1.07684287, -1.10315271], shape=(1798,))
分散の結果
[12]:
fcov
[12]:
array([0.0006267 , 0.00053271, 0.00095938, ..., 0.00067901, 0.00066522,
0.00055919], shape=(1798,))
予測値の平均二乗誤差の出力
[13]:
np.mean((fmean-t_test)**2)
[13]:
np.float64(0.006925305425496946)
得られた回帰モデルについて、どの特徴量がどのくらい重要なのかを調べるための簡単な指標として permutation importance (PI)があります。 PHYSBOでは get_permutation_importance 関数で計算できます。
[14]:
pi_mean, pi_std = gp.get_permutation_importance(X_train, t_train, n_perm=100)
[15]:
features = list(range(len(pi_mean)))
plt.figure(figsize=(8, 5))
plt.barh(
features,
pi_mean,
xerr=pi_std,
)
plt.gca().invert_yaxis()
plt.yticks(features)
plt.xlabel("Permutation Importance")
plt.ylabel("Features")
plt.tight_layout()
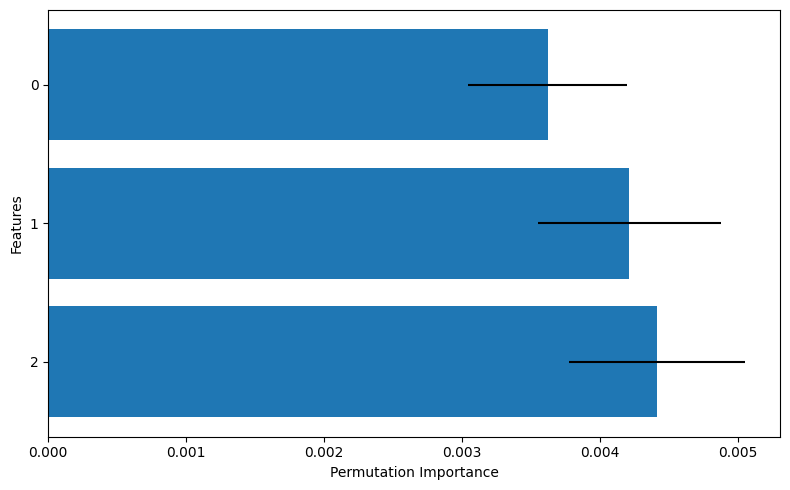
このグラフにおいて、棒グラフはPIの平均値を、線分は標準偏差を示しており、0番の特徴量と比べて1,2番の特徴量のほうが重要そうだ、ということが読み取れます。
gp.model だけではなく, policy も get_permutation_importance 関数を持っています。 使い方は policy.get_permutation_importance(n_perm) です。 policy では保存してある学習済みデータに対してPIを計算するため、 model とは違い、改めて渡す必要はありません。
訓練済みモデルによる予測
学習済みモデルのパラメタをgp_paramsとして読み出し、これを用いた予測を行います。
gp_paramsおよび学習データ(X_train, t_train)を記憶しておくことで、訓練済みモデルによる予測が可能となります。
学習されたパラメタを準備(学習の直後に行う必要あり)
[16]:
#学習したパラメタを1次元配列として準備
gp_params = np.append(np.append(gp.lik.params, gp.prior.mean.params), gp.prior.cov.params)
gp_params
[16]:
array([-2.44630277, -1.06536273, -0.64183368, -2.49190006])
学習に利用したモデルと同様のモデルをgpとして準備
[17]:
#共分散の定義 (ガウシアン)
cov = physbo.gp.cov.Gauss( X_train.shape[1],ard = False )
#平均の定義
mean = physbo.gp.mean.Const()
#尤度関数の定義 (ガウシアン)
lik = physbo.gp.lik.Gauss()
#ガウス過程モデルの生成
gp = physbo.gp.Model(lik=lik,mean=mean,cov=cov)
学習済みのパラメタをモデルに入力し予測を実行
[18]:
#学習済みのパラメタをガウス過程に入力
gp.set_params(gp_params)
#テストデータの平均値(予測値)および分散を計算
gp.prepare(X_train, t_train)
fmean = gp.get_post_fmean(X_train, X_test)
fcov = gp.get_post_fcov(X_train, X_test)
予測の結果
[19]:
fmean
[19]:
array([-1.04749842, -0.99756623, -1.09935748, ..., -1.07561436,
-1.07684287, -1.10315271], shape=(1798,))
分散の結果
[20]:
fcov
[20]:
array([0.0006267 , 0.00053271, 0.00095938, ..., 0.00067901, 0.00066522,
0.00055919], shape=(1798,))
予測値の平均二乗誤差の出力
[21]:
np.mean((fmean-t_test)**2)
[21]:
np.float64(0.006925305425496946)
注意事項
今回のチュートリアルでは、事前に登録されている\(X\) と同じものを利用して予測を行いました。 学習済みのモデルを利用して \(X\) に含まれていないパラメータ \(X_\text{new}\) に対して予測をしたい場合には、 学習モデルで使用したデータ \(X\) の平均(\(X_\text{mean}\))と標準偏差(\(X_\text{std}\) )を求めていただいたうえで、
\(X_\text{new} = (X_\text{new} - X_\text{mean}) / X_\text{std}\)
の変形を行うことで予測を行うことができます。 また、渡す際のデータ形式はndarray形式になっています。 そのため、\(X_\text{new}\)が一つのデータの場合には事前に変換する必要があります。 例えば、\(X_\text{new}\)が実数である場合には、 X_new = np.array(X_new).reshape(1) などとして変換する必要があります。