多目的最適化¶
\(y \prec y^{'}\Longleftrightarrow \forall \ i \le p, y_i \le y^{'}_i \land \exists \ j \le p, y_j < y^{'}_j\)
PHYSBOでは、パレート解を効率的に求めるためのベイズ最適化手法を実装しています。
[1]:
import numpy as np
import matplotlib.pyplot as plt
import physbo
%matplotlib inline
テスト関数¶
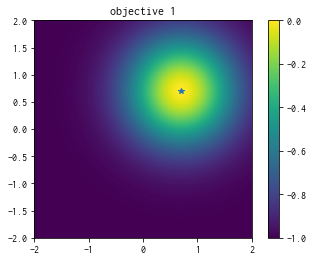
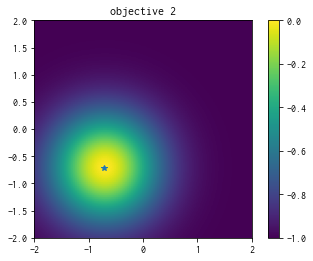
\(y_1\) と \(y_2\) はそれぞれ \(x_1 = x_2 = \cdots x_N = 1/\sqrt{N}\) と \(x_1 = x_2 = \cdots x_N = -1/\sqrt{N}\) に最小値があり、その値はともに0です。また、上界は1 です。
PHYSBO は最大化問題を仮定するため、-1を掛けたものをあらためて目的関数とします。
参考文献
Van Veldhuizen, David A. Multiobjective evolutionary algorithms: classifications, analyses, and new innovations. No. AFIT/DS/ENG/99-01. AIR FORCE INST OF TECH WRIGHT-PATTERSONAFB OH SCHOOL OF ENGINEERING, 1999.
[2]:
def vlmop2_minus(x):
n = x.shape[1]
y1 = 1 - np.exp(-1 * np.sum((x - 1/np.sqrt(n)) ** 2, axis = 1))
y2 = 1 - np.exp(-1 * np.sum((x + 1/np.sqrt(n)) ** 2, axis = 1))
return np.c_[-y1, -y2]
探索候補データの準備¶
入力空間 \(\vec{x}\) は 2次元とし、[-2, 2] × [-2, 2] の上で候補点をグリッド状に生成します。
[3]:
import itertools
a = np.linspace(-2,2,101)
test_X = np.array(list(itertools.product(a, a)))
[4]:
test_X
[4]:
array([[-2. , -2. ],
[-2. , -1.96],
[-2. , -1.92],
...,
[ 2. , 1.92],
[ 2. , 1.96],
[ 2. , 2. ]])
[5]:
test_X.shape
[5]:
(10201, 2)
simulator の定義¶
[6]:
class simulator(object):
def __init__(self, X):
self.t = vlmop2_minus(X)
def __call__( self, action):
return self.t[action]
[7]:
simu = simulator(test_X)
関数のプロット¶
1つ目の目的関数¶
[8]:
plt.figure()
plt.imshow(simu.t[:,0].reshape((101,101)), vmin=-1.0, vmax=0.0, origin="lower", extent=[-2.0, 2.0, -2.0, 2.0])
plt.title("objective 1")
plt.colorbar()
plt.plot([1.0/np.sqrt(2.0)], [1.0/np.sqrt(2.0)], '*')
plt.show()
2つ目の目的関数¶
[9]:
# plot objective 2
plt.figure()
plt.imshow(simu.t[:,1].reshape((101,101)), vmin=-1.0, vmax=0.0, origin="lower", extent=[-2.0, 2.0, -2.0, 2.0])
plt.title("objective 2")
plt.colorbar()
plt.plot([-1.0/np.sqrt(2.0)], [-1.0/np.sqrt(2.0)], '*')
plt.show()
最適化の実行¶
policy のセット¶
policy_mo を利用します。num_objectives に目的関数の数を指定してください。[10]:
policy = physbo.search.discrete.policy_mo(test_X=test_X, num_objectives=2)
policy.set_seed(0)
policy (目的関数が1つの場合)と同じく、random_search または bayes_search メソッドを呼ぶことで最適化を行います。policy とおおよそ共通しています。ランダムサーチ¶
[ ]:
policy = physbo.search.discrete.policy_mo(test_X=test_X, num_objectives=2)
policy.set_seed(0)
res_random = policy.random_search(max_num_probes=50, simulator=simu)
disp_pareto_set=True と指定します。[ ]:
policy = physbo.search.discrete.policy_mo(test_X=test_X, num_objectives=2)
policy.set_seed(0)
res_random = policy.random_search(max_num_probes=50, simulator=simu, disp_pareto_set=True)
結果の確認¶
#### 評価値の履歴
[ ]:
res_random.fx[0:res_random.num_runs]
パレート解の取得¶
[14]:
front, front_num = res_random.export_pareto_front()
front, front_num
[14]:
(array([[-0.95713719, -0.09067194],
[-0.92633083, -0.29208351],
[-0.63329589, -0.63329589],
[-0.52191048, -0.72845916],
[-0.26132949, -0.87913689],
[-0.17190645, -0.91382463]]),
array([40, 3, 19, 16, 29, 41]))
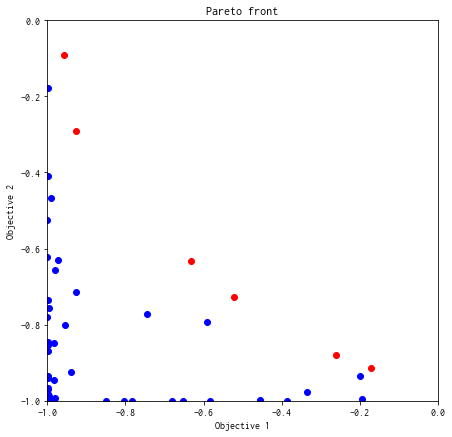
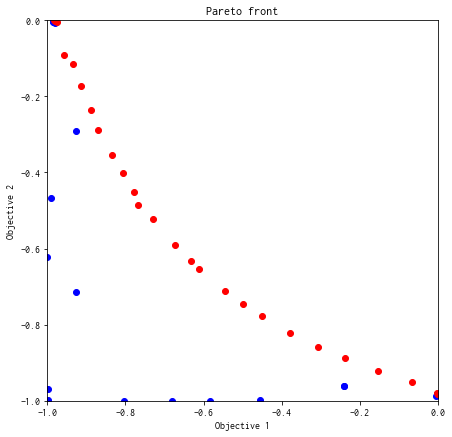
解(評価値)のプロット¶
これ以降、図示する空間が \(y = (y_1, y_2)\) であり \(x = (x_1, x_2)\) ではないことにあらためて注意してください。
赤のプロットがパレート解です。
[15]:
def plot_pareto_front(res):
front, front_num = res.export_pareto_front()
dominated = [i for i in range(res.num_runs) if i not in front_num]
points = res.fx[dominated, :]
plt.figure(figsize=(7, 7))
plt.scatter(res.fx[dominated,0], res.fx[dominated,1], c = "blue")
plt.scatter(front[:, 0], front[:, 1], c = "red")
plt.title('Pareto front')
plt.xlabel('Objective 1')
plt.ylabel('Objective 2')
plt.xlim([-1.0,0.0])
plt.ylim([-1.0,0.0])
[16]:
plot_pareto_front(res_random)
劣解領域 (dominated region) の体積を計算¶
res_random.pareto.volume_in_dominance(ref_min, ref_max) は、 ref_min, ref_max で指定された矩形(hyper-rectangle) 中の劣解領域体積を計算します。
[17]:
res_random.pareto.volume_in_dominance([-1,-1],[0,0])
[17]:
0.2376881844865093
ベイズ最適化¶
多目的の場合の bayes_search では、score には以下のいずれかを指定します。
HVPI (Hypervolume-based Probability of Improvement)
EHVI (Expected Hyper-Volume Improvement)
TS (Thompson Sampling)
以下、score を変えてそれぞれ 50回 (ランダムサーチ10回 + ベイズ最適化 40回) 評価を行います。
HVPI (Hypervolume-based Probability of Improvement)¶
多次元の目的関数空間における非劣解領域 (non-dominated region) の改善確率を score として求めます。
参考文献
Couckuyt, Ivo, Dirk Deschrijver, and Tom Dhaene. “Fast calculation of multiobjective probability of improvement and expected improvement criteria for Pareto optimization.” Journal of Global Optimization 60.3 (2014): 575-594.
[ ]:
policy = physbo.search.discrete.policy_mo(test_X=test_X, num_objectives=2)
policy.set_seed(0)
policy.random_search(max_num_probes=10, simulator=simu)
res_HVPI = policy.bayes_search(max_num_probes=40, simulator=simu, score='HVPI', interval=10)
EHVI (Expected Hyper-Volume Improvement)¶
多次元の目的関数空間における非劣解領域 (non-dominated region) の改善期待値を score として求めます。
参考文献
Couckuyt, Ivo, Dirk Deschrijver, and Tom Dhaene. “Fast calculation of multiobjective probability of improvement and expected improvement criteria for Pareto optimization.” Journal of Global Optimization 60.3 (2014): 575-594.
[ ]:
policy = physbo.search.discrete.policy_mo(test_X=test_X, num_objectives=2)
policy.set_seed(0)
policy.random_search(max_num_probes=10, simulator=simu)
res_EHVI = policy.bayes_search(max_num_probes=40, simulator=simu, score='EHVI', interval=10)
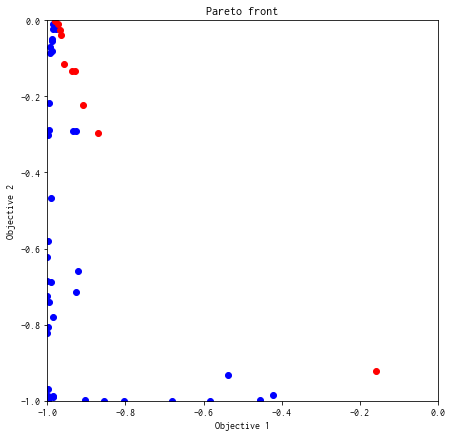
TS (Thompson Sampling)¶
参考文献
Yahyaa, Saba Q., and Bernard Manderick. “Thompson sampling for multi-objective multi-armed bandits problem.” Proc. Eur. Symp. Artif. Neural Netw., Comput. Intell. Mach. Learn.. 2015.
[ ]:
policy = physbo.search.discrete.policy_mo(test_X=test_X, num_objectives=2)
policy.set_seed(0)
policy.random_search(max_num_probes=10, simulator=simu)
res_TS = policy.bayes_search(max_num_probes=40, simulator=simu, score='TS', interval=10, num_rand_basis=5000)
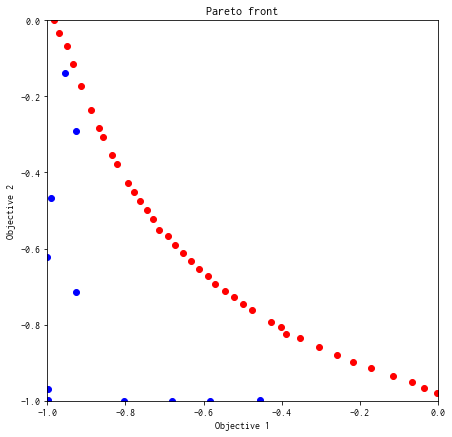
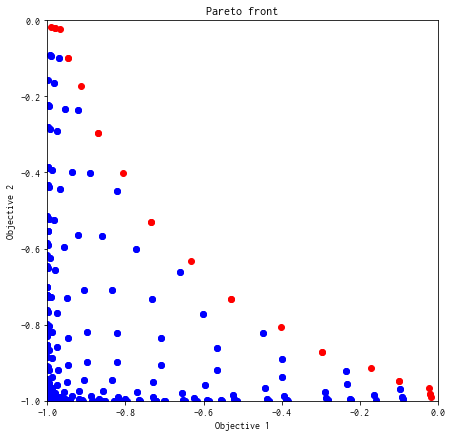
付録:全探索¶
random_search で max_num_probes に全データ数 (N = test_X.shape[0]) を渡すと手軽に全探索できます。[ ]:
test_X_sparse = np.array(list(itertools.product(np.linspace(-2, 2, 21), repeat=2)))
simu_sparse = simulator(test_X_sparse)
policy = physbo.search.discrete.policy_mo(test_X=test_X_sparse, num_objectives=2)
policy.set_seed(0)
N = test_X_sparse.shape[0]
res_all = policy.random_search(max_num_probes=N, simulator=simu_sparse)
[28]:
plot_pareto_front(res_all)
[29]:
res_all.pareto.volume_in_dominance([-1,-1],[0,0])
[29]:
0.30051687493437484
[ ]: