3.1. 基本的な使い方¶
網羅計算のためのバッチジョブスクリプト生成ツール moller を使うには、入力ファイルとして実行内容を記述する構成定義ファイルを用意した後、プログラム moller を実行します。生成されたバッチジョブスクリプトを対象とするスーパーコンピュータシステムに転送し、バッチジョブを投入して計算を行います。
以下では、 docs/tutorial/moller ディレクトリにあるサンプルを例にチュートリアルを実施します。
構成定義ファイルを作成する¶
構成定義ファイルにはバッチジョブで実行する処理の内容を記述します。 ここで、バッチジョブとはスーパーコンピュータシステム等のジョブスケジューラに投入する実行内容を指します。それに対し、moller が対象とするプログラムの多重実行において、多重実行される一つのパラメータセットでの実行内容をジョブと呼ぶことにします。一つのジョブはいくつかの処理単位からなり、その処理単位をタスクと呼びます。moller ではタスクごとに多重実行し、タスクの前後で同期がとられます。
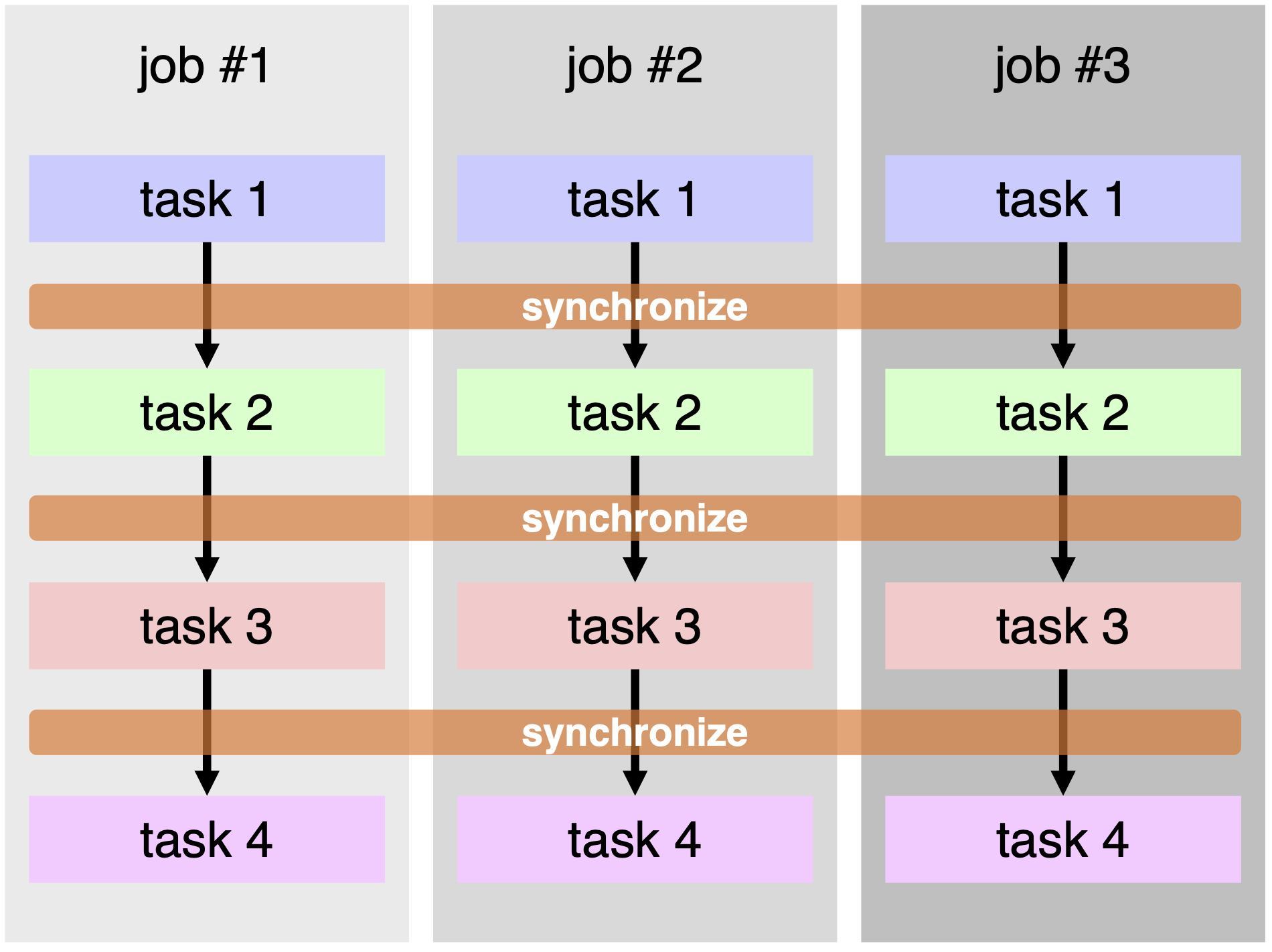
図 3.1 例: 一つのバッチジョブ内で job #1〜#3 の 3つのジョブを実行する。ジョブはそれぞれ異なるパラメータセットなどに対応する。ジョブの実行内容は task 1〜4 の一連のタスクからなる。タスクごとに job #1〜#3 の処理を並列に行う。¶
以下に構成定義ファイルのサンプルを記載します。構成定義ファイルは YAMLフォーマットのテキストファイルで、実行するプラットフォームやバッチジョブのパラメータと、タスクの処理内容、前処理・後処理を記述します。
name: testjob
description: Sample task file
platform:
system: ohtaka
queue: i8cpu
node: 1
elapsed: 00:10:00
prologue:
code: |
module purge
module load oneapi_compiler/2023.0.0 openmpi/4.1.5-oneapi-2023.0.0-classic
ulimit -s unlimited
source /home/issp/materiapps/intel/parallel/parallelvars-20210622-1.sh
jobs:
start:
parallel: false
run: |
echo "start..."
hello:
description: hello world
node: [1,1]
run: |
echo "hello world." > result.txt
sleep 2
hello_again:
description: hello world again
node: [1,1]
run: |
echo "hello world again." >> result.txt
sleep 2
epilogue:
code: |
echo "done."
date
platformセクションでは、実行するプラットフォームの種類を指定します。この場合は、物性研システムB(ohtaka)での設定をしています。
prologueセクションでは、バッチジョブの前処理を記述します。タスクを実行する前に実行する共通のコマンドラインを記述します。
jobsセクションでは、タスクの処理内容を記述します。ジョブで実行する一連のタスクを、タスク名をキー、処理内容を値として記述するテーブルの形式で記述します。
この例では、最初に"start..."を出力するタスクを start というタスク名で定義しています。
ここでは parallel = false に設定しています。この場合、ジョブ単位での並列は行われず、run に記述した内容が逐次的に実行されます。
次に、"hello world."を出力するタスクを hello world というタスク名で定義しています。
ここでは parallel が設定されていないので、 paralle = true として扱われます。この場合、ジョブ単位での並列が行われます。
同様に、次に "hello world again." を出力するタスクを hello_again というタスク名で定義しています。
最後に、epilogueセクションでは、バッチジョブの後処理を記述します。タスクを実行した後に実行する共通のコマンドラインを記述します。
仕様の詳細については ファイルフォーマット の章を参照してください。
バッチジョブスクリプトを生成する¶
構成定義ファイル(input.yaml)を入力として moller を実行します。
$ moller -o job.sh input.yaml
バッチジョブスクリプトが生成され出力されます。出力先は構成定義ファイル内のパラメータ、または、コマンドラインの -o または --output オプションで指定するファイルです。 両方指定されている場合はコマンドラインパラメータが優先されます。いずれも指定がない場合は標準出力に書き出されます。
必要に応じて mollerで生成したバッチジョブスクリプトを対象のシステムに転送します。 なお、スクリプトの種類は bash スクリプトです。ジョブ実行時に使用するシェルを bash に設定しておく必要があります。(ログインシェルを csh系などにしている場合は注意)
リストファイルを作成する¶
実行するジョブのリストを作成します。moller では、ジョブごとに個別のディレクトリを用意し、そのディレクトリ内で各ジョブを実行する仕様になっています。 対象となるディレクトリのリストを格納したファイルを、たとえば以下のコマンドで、リストファイルとして作成します。
$ /usr/bin/ls -1d * > list.dat
チュートリアルには、データセットとリストファイルを作成するユーティリティープログラムが付属しています。
$ bash ./make_inputs.sh
を実行すると、 output ディレクトリの下にデータセットに相当する dataset-0001 〜 dataset-0020 のディレクトリと、リストファイル list.dat が作成されます。
網羅計算を実行する¶
mollerで生成したバッチジョブスクリプトをジョブスケジューラに投入します。この例ではジョブスクリプトと入力ファイルを output ディレクトリにコピーし、 output に移動してジョブを投入しています。
$ cp job.sh input.yaml output/ $ cd output $ sbatch job.sh list.dat
ジョブが実行されると、リストに記載されたディレクトリにそれぞれ "result.txt" というファイルが生成されます。 "result.txt" には、ジョブ実行結果の "hello world.", "hello world again." という文字列が出力されていることが確認できます。
実行状況を確認する¶
タスクの実行状況はログファイルに出力されます。ログを収集してジョブごとに実行状況を一覧するツール moller_status が用意されています。ジョブを実行するディレクトリで以下を実行します。
$ moller_status input.yaml list.dat
引数には構成定義ファイル input.yaml とリストファイル list.dat を指定します。リストファイルは省略可能で、その場合はログファイルからジョブの情報を収集します。
出力サンプルを以下に示します。
| job | hello | hello_again |
|--------------|---------|---------------|
| dataset-0001 | o | o |
| dataset-0002 | o | o |
| dataset-0003 | o | o |
| dataset-0004 | o | o |
| dataset-0005 | o | o |
| dataset-0006 | o | o |
| dataset-0007 | o | o |
| dataset-0008 | o | o |
| dataset-0009 | o | o |
| dataset-0010 | o | o |
| dataset-0011 | o | o |
| dataset-0012 | o | o |
| dataset-0013 | o | o |
| dataset-0014 | o | o |
| dataset-0015 | o | o |
| dataset-0016 | o | o |
| dataset-0017 | o | o |
| dataset-0018 | o | o |
| dataset-0019 | o | o |
| dataset-0020 | o | o |
「o」は正常終了したタスク、「x」はエラーになったタスク、「-」は前のタスクがエラーになったためスキップされたタスク、「.」は未実行のタスクを示します。 今回は全て正常終了していることがわかります。
失敗したタスクを再実行する¶
タスクが失敗した場合、そのジョブ内の後続のタスクは実行されません。以下は、各タスクが 10% の確率で失敗するケースの実行例です。
| job | task1 | task2 | task3 |
|--------------|---------|---------|---------|
| dataset_0001 | o | o | o |
| dataset_0002 | o | x | - |
| dataset_0003 | x | - | - |
| dataset_0004 | x | - | - |
| dataset_0005 | o | o | o |
| dataset_0006 | o | o | o |
| dataset_0007 | o | x | - |
| dataset_0008 | o | o | o |
| dataset_0009 | o | o | x |
| dataset_0010 | o | o | o |
| dataset_0011 | o | o | o |
| dataset_0012 | o | o | o |
| dataset_0013 | o | x | - |
| dataset_0014 | o | o | o |
| dataset_0015 | o | o | o |
| dataset_0016 | o | o | o |
| dataset_0017 | o | o | o |
| dataset_0018 | o | o | o |
| dataset_0019 | o | o | o |
| dataset_0020 | o | o | o |
dataset_0003, dataset_0004 は task1 が失敗し、後続の task2, task3 は実行されていません。その他の dataset は task1 が成功し、次の task2 が実行されています。このように、各ジョブは他のジョブとは独立に実行されます。
失敗したタスクを再実行するには、バッチジョブに retry のオプションをつけて再実行します。 SLURMジョブスケジューラ (例: 物性研システムB) の場合は次のようにバッチジョブを投入します。
$ sbatch job.sh --retry list.dat
PBSジョブスケジューラ (例: 物性研システムC) の場合はジョブスクリプトを編集し、 retry=0 の行を retry=1 に変更して、バッチジョブを再投入します。
| job | task1 | task2 | task3 |
|--------------|---------|---------|---------|
| dataset_0001 | o | o | o |
| dataset_0002 | o | o | x |
| dataset_0003 | o | x | - |
| dataset_0004 | o | o | o |
| dataset_0005 | o | o | o |
| dataset_0006 | o | o | o |
| dataset_0007 | o | o | o |
| dataset_0008 | o | o | o |
| dataset_0009 | o | o | o |
| dataset_0010 | o | o | o |
| dataset_0011 | o | o | o |
| dataset_0012 | o | o | o |
| dataset_0013 | o | o | o |
| dataset_0014 | o | o | o |
| dataset_0015 | o | o | o |
| dataset_0016 | o | o | o |
| dataset_0017 | o | o | o |
| dataset_0018 | o | o | o |
| dataset_0019 | o | o | o |
| dataset_0020 | o | o | o |
エラーになったタスクのみ再実行されます。上記の例では、dataset_0003 は task1 が再実行され正常終了し、次の task2 の実行に失敗しています。dataset_0004 は task1, task2, task3 が正常に実行されています。task3 まで全て正常終了しているデータ・セットに対しては何も実行しません。
なお、再実行の際にリストファイルは変更しないでください。リストファイル内の順番でジョブを管理しているため、変更すると正しく再実行されません。