この jupyter notebook ファイルは ISSP Data Repository (develop branch) から入手できます。
PHYSBO の基本
PHYSBO は physbo という名前のパッケージとして提供されています。 physbo を含め、チュートリアルで使うパッケージをインポートします。
[1]:
import numpy as np
import matplotlib.pyplot as plt
import physbo
このチュートリアルの問題設定
本チュートリアルでは例として、一次元の関数 \(f(x) = 3 x^4 + 4 x ^3 + 1.0\) の最小化問題を扱います。 なお、この関数は \(x=-1.0\) で最小値 \(f(-1.0) = 0.0\) を取ります。
[2]:
def fn(x):
return 3 * x**4 + 4 * x**3 + 1.0
探索候補データの準備
関数を探索する空間を定義します。 PHYSBOではあらかじめ探索する候補点を np.ndarray で作っておく必要があります。 行列の大きさは (N, d) で、N は探索候補点の数、d は探索空間の次元数です。 各次元で等間隔に分割する場合には physbo.search.utility.make_grid を用いると便利です。 以下の例では、探索空間 X を x_min = -2.0 から x_max = 2.0 まで window_num=10001 分割で刻んだグリッドで定義しています。
[3]:
window_num=10001
x_max = [2.0]
x_min = [-2.0]
X = physbo.search.utility.make_grid(x_min, x_max, window_num)
X.shape
[3]:
(10001, 1)
simulator の定義
PHYSBOでは実際に目的関数を計算する関数(あるいは Callable オブジェクト)を simulator と呼びます。
simulator は探索点のインデックス action を受け取り、その点の目的関数を返します。 複数点を一度に計算できるように、一般的に action は np.ndarray の形式を取ります。
PHYSBOでは目的関数値が最大となる ものを求める仕様になっているため、今回の例のような最小化問題では、目的関数の値に -1 をかけたものを返すことで最大化問題に帰着させます。
physbo.search.utility.Simulator を使うと、上記の条件を満たすような simulator を簡単に作成できます。
[4]:
simulator = physbo.search.utility.Simulator(X, fn, negate=True)
最適化の実行
Policy のセット
まず、最適化の Policy をセットします。
test_X に探索候補の行列 (numpy.array) を指定します。
[5]:
# policy のセット
policy = physbo.search.discrete.Policy(test_X=X)
# シード値のセット
policy.set_seed(0)
policy をセットした段階では、まだ最適化は行われません。 policy に対して以下のメソッドを実行することで、最適化を行います。
random_searchbayes_search
これらのメソッドに先ほど定義した simulator と探索ステップ数を指定すると、探索ステップ数だけ以下のループが回ります。
パラメータ候補の中から次に実行するパラメータを選択
選択されたパラメータで
simulatorを実行で返されるパラメータはデフォルトでは1つですが、1ステップで複数のパラメータを返すことも可能です。 詳しくは「複数候補を一度に探索する」の項目を参照してください。
また、上記のループを PHYSBO の中で回すのではなく、i) と ii) を別個に外部から制御することも可能です。つまり、PHYSBO から次に実行するパラメータを提案し、その目的関数値をPHYSBOの外部で何らかの形で評価し(例えば、数値計算ではなく、実験による評価など)、それをPHYSBOの外部で何らかの形で提案し、評価値をPHYSBOに登録する、という手順が可能です。詳しくは、チュートリアルの「インタラクティブに実行する」の項目を参照してください。
ランダムサーチ
まず初めに、ランダムサーチを行ってみましょう。
ベイズ最適化の実行には、目的関数値が2つ以上求まっている必要があるため(初期に必要なデータ数は、最適化したい問題、パラメータの次元dに依存して変わります)、まずランダムサーチを実行します。
引数
max_num_probes: 探索ステップ数simulator: 目的関数のシミュレータ
[6]:
res = policy.random_search(max_num_probes=20, simulator=simulator)
0001-th step: f(x) = -51.387604 (action=9395)
current best f(x) = -51.387604 (best action=9395)
0002-th step: f(x) = -0.581263 (action=3583)
current best f(x) = -0.581263 (best action=3583)
0003-th step: f(x) = -0.827643 (action=4015)
current best f(x) = -0.581263 (best action=3583)
0004-th step: f(x) = -14.220707 (action=154)
current best f(x) = -0.581263 (best action=3583)
0005-th step: f(x) = -34.192764 (action=8908)
current best f(x) = -0.581263 (best action=3583)
0006-th step: f(x) = -31.595527 (action=8819)
current best f(x) = -0.581263 (best action=3583)
0007-th step: f(x) = -0.361729 (action=3269)
current best f(x) = -0.361729 (best action=3269)
0008-th step: f(x) = -0.755839 (action=3870)
current best f(x) = -0.361729 (best action=3269)
0009-th step: f(x) = -10.883996 (action=370)
current best f(x) = -0.361729 (best action=3269)
0010-th step: f(x) = -0.150313 (action=2949)
current best f(x) = -0.150313 (best action=2949)
0011-th step: f(x) = -3.885764 (action=6926)
current best f(x) = -0.150313 (best action=2949)
0012-th step: f(x) = -3.525070 (action=6851)
current best f(x) = -0.150313 (best action=2949)
0013-th step: f(x) = -3.252476 (action=6789)
current best f(x) = -0.150313 (best action=2949)
0014-th step: f(x) = -7.524212 (action=641)
current best f(x) = -0.150313 (best action=2949)
0015-th step: f(x) = -16.136719 (action=8125)
current best f(x) = -0.150313 (best action=2949)
0016-th step: f(x) = -1.439937 (action=6090)
current best f(x) = -0.150313 (best action=2949)
0017-th step: f(x) = -9.415991 (action=480)
current best f(x) = -0.150313 (best action=2949)
0018-th step: f(x) = -4.854365 (action=925)
current best f(x) = -0.150313 (best action=2949)
0019-th step: f(x) = -1.042368 (action=5523)
current best f(x) = -0.150313 (best action=2949)
0020-th step: f(x) = -19.075990 (action=8288)
current best f(x) = -0.150313 (best action=2949)
実行すると、各ステップの目的関数値とその action ID、現在までのベスト値とその action ID に関する情報が以下のように出力されます。
0020-th step: f(x) = -19.075990 (action=8288)
current best f(x) = -0.150313 (best action=2949)
こうした出力は is_disp=False とすると抑制できます。
ベイズ最適化
続いて、ベイズ最適化を以下のように実行します。
引数
max_num_probes: 探索ステップ数simulator: 目的関数のシミュレータ (simulator クラスのオブジェクト)score: 獲得関数(acquisition function) のタイプ。以下のいずれかを指定します。TS (Thompson Sampling)
EI (Expected Improvement)
PI (Probability of Improvement)
interval: 指定したインターバルごとに、ハイパーパラメータを学習します。 負の値を指定すると、ハイパーパラメータの学習は行われません。 0 を指定すると、ハイパーパラメータの学習は最初のステップでのみ行われます。num_rand_basis: 基底関数の数。0を指定すると、Bayesian linear modelを利用しない通常のガウス過程が使用されます。
[7]:
res = policy.bayes_search(
max_num_probes=50,
simulator=simulator,
score="TS",
interval=0,
num_rand_basis=500,
is_disp=False,
)
結果の確認
physbo.search.discrete.results.history) として返されます。res.fx: simulator (目的関数) の評価値の履歴。res.chosen_actions: simulator を評価したときの action ID (パラメータ) の履歴。fbest, best_action= res.export_all_sequence_best_fx(): simulator を評価した全タイミングにおけるベスト値とその action ID (パラメータ)の履歴。res.total_num_search: simulator のトータル評価数。
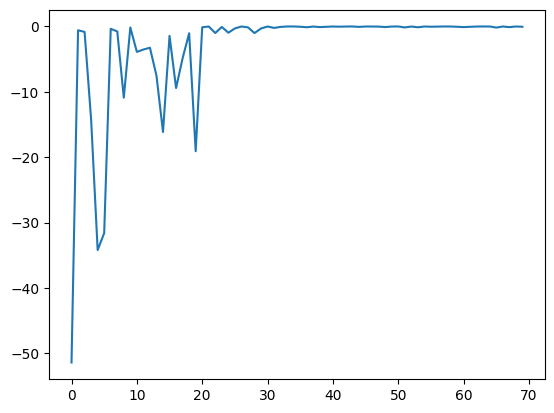
res.fx, best_fx はそれぞれ res.total_num_search までの範囲を指定します。[8]:
plt.plot(res.fx[0:res.total_num_search])
[8]:
[<matplotlib.lines.Line2D at 0x11142ecd0>]
[9]:
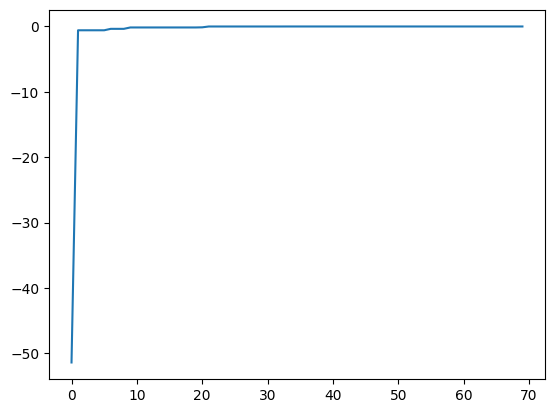
best_fx, best_action = res.export_all_sequence_best_fx()
plt.plot(best_fx)
[9]:
[<matplotlib.lines.Line2D at 0x113012450>]
結果のシリアライズ
探索結果は save メソッドにより外部ファイルに保存できます。
[10]:
res.save('search_result.npz')
[11]:
del res
保存した結果ファイルは以下のようにロードすることができます。
[12]:
res = physbo.search.discrete.History()
res.load('search_result.npz')
最後に、一番よいスコアを持つ候補は以下のようにして表示することができます。正しい解 x=-1に行き着いていることがわかります。
[13]:
print(X[int(best_action[-1])])
[-1.002]
回帰
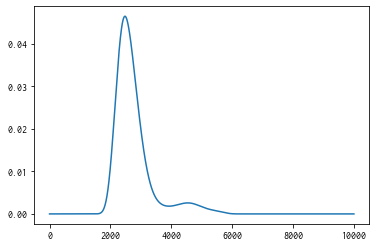
get_post_fmean, get_post_fcov メソッドでガウス過程(事後分布)の期待値と分散を計算可能です。
[14]:
mean = policy.get_post_fmean(X)
var = policy.get_post_fcov(X)
std = np.sqrt(var)
x = X[:,0]
fig, ax = plt.subplots()
ax.plot(x, mean)
ax.fill_between(x, (mean-std), (mean+std), color='b', alpha=.1)
[14]:
<matplotlib.collections.FillBetweenPolyCollection at 0x112ff82d0>
獲得関数
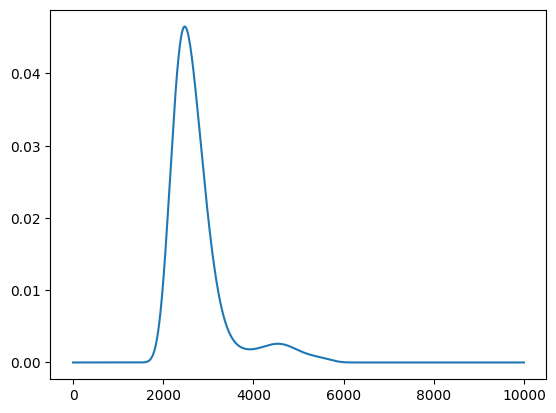
get_score メソッドで獲得関数を計算可能です。
[15]:
score = policy.get_score(mode="EI", xs=X)
plt.plot(score)
[15]:
[<matplotlib.lines.Line2D at 0x11346c590>]
並列化
PHYSBO は全候補点に対する獲得関数の計算をMPI を用いて並列化出来ます。 MPI 並列には mpi4py を用います。
並列化を有効化するには、 policy のコンストラクタのキーワード引数 comm に MPI コミュニケータ、たとえば MPI.COMM_WORLD を渡してください。
[16]:
# from mpi4py import MPI
# policy = physbo.search.discrete.Policy(X=test_X, comm=MPI.COMM_WORLD)